
Converting PDF files into separate images and generating full text furthers their use on the platform
While images can be uploaded and viewed on the platform, other files are mainly uploaded for storage. It's need to downloaded a file again to see its content. Extracting the images from PDF files is a great way to make better use of their content. Converting the image text to actual text during the extration process further enables sophisticated full-text search capabilities with automatic recognition of embedded text.
PDFs can be converted into images by using the PDF extraction functionality. First you need to upload a PDF file to the Files section of a resource. Then you can initiate the extraction process, which runs in the background. After the extraction is finished, the new images are available in the media section, ready to use!
Follow the steps below to extract images form PDF files.
Uploading a PDF file
- In the Files section click on the Add+ button. Your file explorer will pop up, select the PDF you want to upload from your computer.

- Select the file you want to upload from your computer. A progress bar indicates that file is being uploaded.
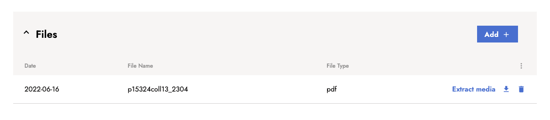
- Once the upload is completed, the file is displayed in the list with the upload date, file name, file type and options to extract media, download, or delete the file.
Extracting images with OCR from a PDF file
- Initiate the extraction. Click on Extract media in the line of the file from which you want to extract images.

- Enable the text extraction. After clicking on Extract media, a box is displayed to either extract the media only or to extract with Optical Character Recognition (OCR) to convert the media from image text to actual text.
- When you click on No, just extract media, the pages are extracted as pure images.
-
When you click on Yes, extract media with OCR, the pages are extracted and converted to scans that are full-text-readable.

- When you click on No, just extract media, the pages are extracted as pure images.
- Extraction is in progress. Depending on the file size and page count, the extraction may take several minutes. All this happens in the background, so while waiting, you can leave this page and continue using the platform. You will be notified via email once the extraction is finished.
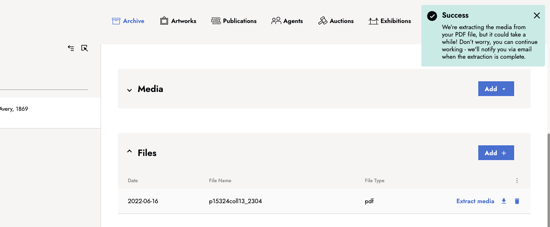
- Finish extraction. You have successfully extracted and converted images from a PDF file, congratulations! Each page of the PDF is now available as a separate image in the media section. When accessing each item, you will see the full-text-readable icon on the left to indicate that the media has been converted and is now text. As such, you can perform the full-text search.
If the media is not visible the extraction process may still be in progress. Reload the page and check the media section again.